![[Index]](haus.gif)
![[Back]](back.gif)
![[Forward]](forward.gif)
Den Übersetzungsprozeß von CAT2 kann man wie bei vielen anderen Systemen in die Phasen Analyse , Transfer und Generierung gliedern, wobei Analyse und Generierung die linguistischen Ebenen Morphologie, Syntax und Semantik umfassen und der Transfer den konkreten Umsetzungsprozeß von der Quellsprache in die Zielsprache darstellt.

Abbildung 4.1: Phasen des Übersetzungsprozesses
Aus der Sicht des Verarbeitungsmodells von CAT2 ist die Einteilung anders vorzunehmen. Hier kann man die morphologische Analyse, die syntaktische Analyse, die Phase der Baumtransformationen und die morphologische Generierung unterscheiden.

Abbildung 4.2: Phasen der Übersetzung aus Sicht des Verarbeitungsmodells
Die morphologische Analyse hat die Aufgabe, jedem Wort der Eingabe eine Merkmalsstruktur mit morphologischen, syntaktischen und semantischen Merkmalen zuzuordnen. CAT2 besitzt keine eigene morphologische Analyse. Die Einträge in der morphologischen Ebene der Grammatik bilden vielmehr ein Vollformenlexikon, aus welchem die entsprechenden Merkmalsstrukturen ausgelesen werden können.
Da diese Situation äußerst unbefriedigend ist, gibt es die Möglichkeit, die morphologische Analyse von einem externen Programm durchführen zu lassen. Im Moment wird dazu das Programm MPRO verwendet, welches sowohl Komposition und Derivation, als auch Flexion beherrscht, und für viele Sprachen, allerdings in unterschiedlichem Umfang, zur Verfügung steht.
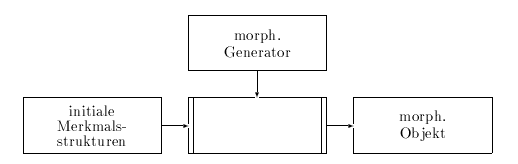
Abbildung 4.3: Erstellung eines morph. Objekts mit Vollformenlexikon
Bei der Verwendung eines Vollformenlexikons wird die morphologische Analyse durch einen simplen Lexikonzugriff ersetzt. Jeder Zeichenkette der Eingabe wird eine initiale Merkmalsstruktur zugewiesen. Diese besteht aus den Merkmalen string und 'word#'. Der Wert von string ist die Zeichenkette selbst und der Wert von 'word#' eine Zahl, die ihre Stellung im Satz repräsentiert. Der Wert des Merkmals string dient als Schlüssel für den Lexikonzugriff. Das bedeutet, daß für jede Zeichenkette, die korrekt verarbeitet werden soll, mindestens ein Eintrag im morphologischen Generator der Quellsprache existieren muß. Dieser Lexikoneintrag wird ausgelesen und mit der initialen Merkmalsstruktur der Zeichenkette unifiziert. Anschließend werden die F-Regeln des Generators genutzt, um Defaultmerkmale und -werte in die Merkmalsstruktur aufzunehmen. Kann kein Lexikoneintrag gefunden werden, der die zu analysierende Zeichenkette enthält, wird das Merkmal lex mit dem Wert '@unknown' belegt.
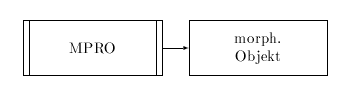
Abbildung 4.4: Erstellung eines morph. Objekts mit MPRO
Die externe morphologische Analyse mittels MPRO liefert ein morphologisches Objekt, das aus Merkmalsstrukturbeschreibungen besteht, die auf die Grammatik von CAT2 abgestimmt sind und genauso verarbeitet werden können, als wären sie durch die Verwendung eines morphologischen Generators entstanden.
Für die Syntaxanalyse wird in CAT2 ein Bottom-Up-Chart-Parser mit einem modifiziertem Earley-Algorithmus verwendet. Dieser erstellt aus einem morphologischem Objekt unter Nutzung eines syntaktischen Generators einen, bzw. bei Mehrdeutigkeit mehrere Syntaxbäume. Der Parser von CAT2 arbeitet ohne Startsymbol, d.h. er ist theoretisch in der Lage, jede beliebige Phrase, die durch die Grammatik definiert wird, zu analysieren. Dadurch wird es möglich, auch einzelne Wörter oder Wortgruppen zu übersetzen.
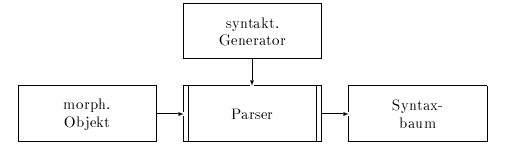
Abbildung 4.5: Syntaktische Analyse in CAT2
Syntaktischer Generator Wie in den vorhergehenden Abschnitten besprochen, besteht der syntaktische Generator aus B-Regeln, die die möglichen syntaktischen Strukturen beschreiben, und F-Regeln, zur Überprüfung und Vervollständigung der Merkmale erstellter Strukturen. Die kleinsten syntaktischen Strukturen, die Blätter eines Syntaxbaumes, werden durch atomare B-Regeln beschrieben. Diese bilden das Lexikon der syntaktischen Ebene.
Morphologisches Objekt Das morphologische Objekt, welches analysiert und in ein syntaktisches überführt werden soll, besteht aus einer Liste von Merkmalsstrukturen. Jede Merkmalsstruktur beschreibt ein Wort der Eingabe. Bei Mehrdeutigkeiten kann ein Wort auch durch mehrere Merkmalsstrukturen beschrieben werden.
Scanner Der Scanner erstellt aus der morphologischen Merkmalsstruktur eines Wortes durch Unifikation mit einer atomaren B-Regel, die das gleiche Lexem repräsentiert, d.h. denselben Wert des Merkmals lex besitzt, ein syntaktisches Objekt. Auf dieses werden dann die F-Regeln des Generators angewendet. Im Erfolgsfall wird das Objekt in einem Chart abgespeichert. Existieren mehrere Merkmalsstrukturen für das Eingabewort, oder werden verschiedene Lexikoneinträge mit dem gleichen Lexem gefunden, wird jeweils ein weiteres syntaktisches Objekt erstellt.
Completer Ist die Phase des Scannens beendet, wird der Completer aktiviert. Dieser versucht aus den bereits abgespeicherten syntaktischen Objekten, größere Syntaxbäume zu erstellen. Für jedes in der letzten Scanner-Phase erstellte Objekt läuft dieselbe Prozedur ab: Es wird eine B-Regel gesucht, die einen Baum beschreibt, dessen äußerster rechter Tochterknoten mit dem Objekt unifizierbar ist. In einem weiteren Schritt werden die anderen Tochterknoten, von rechts beginnend mit bereits erstellten syntaktischen Objekten aufgefüllt. Also mit Wörtern oder Wortgruppen, die sich in der Eingabe links vom aktuellen Wort befinden. Der entstehende Syntaxbaum wird wieder der Überprüfung durch die F-Regeln unterzogen und dann in einem Chart abgespeichert. Danach dient er als neuer Ausgangspunkt für die Erstellung noch größerer Strukturen. Falls es mehrere Möglichkeiten gibt, einen Baum zu erstellen, also mehrere Regeln anwendbar sind, oder die Tochterknoten mit verschiedenen Objekten unifiziert werden können, werden diese Möglichkeiten nacheinander getestet und im Erfolgsfall ein weiteres Objekt erstellt und gespeichert.
Alle weiteren Prozesse bis zur morphologischen Generierung sind Baumtransformationsprozesse zwischen zwei Ebenen der Repräsentation. Für den Transformationsprozess wird ein Translator zwischen den Ebenen und ein Generator für die Zielebene benötigt.
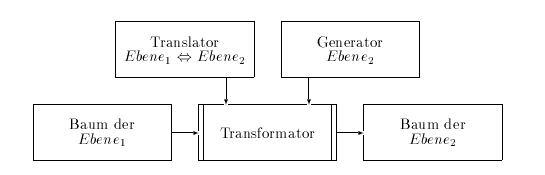
Abbildung 4.6: Baumtransformation
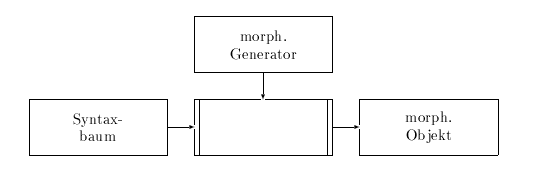
Abbildung 4.7: Morphologische Generierung in CAT2
Ausgangspunkt der morphologischen Generierung ist ein syntaktisches Objekt, ein Syntaxbaum. Das Ziel ist ein morphologisches Objekt, das für jedes Wort des Ausgabesatzes eine Merkmalsstruktur mit dem Merkmal string enthält, dessen Wert die korrekte Zeichenkette der Zielsprache widerspiegelt. Wie bei der Analyse gibt es auch bei der morphologischen Generierung die Möglichkeiten ein externes Programm oder ein Vollformenlexikon zu benutzen. Beide Verfahrensweisen arbeiten wortweise, d.h. die Blätter des Syntaxbaumes dienen nacheinander als Eingabe.
Kann eine normale Übersetzung nicht erfolgen, weil zum Beispiel kein vollständiger Syntaxbaum erstellt werden kann, ist es dennoch oft erwünscht, ein wenigstens teilweise richtiges Ergebnis zu erhalten. Deshalb existiert der Robustmodus.
Aus den Teilbäumen, die mit dem ersten Wort der Eingabe beginnen, wird der größte ausgewählt. Der nächste zu übersetzende Teilbaum muß dann an diesen anschließen, usw. Diese Auswahlmethode ist relativ willkürlich, da nicht gesichert ist, daß die linguistisch sinnvollste Gliederung aus den möglichen ausgewählt wurde.