![[Index]](haus.gif)
![[Back]](back.gif)
![[Forward]](forward.gif)
Kapitel 2 : Der Grammatikformalismus
Entsprechend den im vorigen Abschnitt angesprochenen unterschiedlichen Ebenen der Repräsentation werden im CAT2 auch die dazugehörigen linguistischen Strukturen unterschieden. Es findet eine Einteilung in morphologische Objekte, syntaktische Strukturen und relationale Darstellungsformen statt.
Ein morphologisches Objekt besteht aus einer Liste von einzelnen Wörtern. Ein Wort wird durch eine oder, im Fall einer Mehrdeutigkeit, durch mehrere Merkmalsstrukturen repräsentiert.
Beispiel 2.1: Darstellung eines morphologischen Objektes
[
[{'word#'=1,string=the,lex=art,cat=det,type=def,agr={per=3}}],
[{'word#'=2,string=council,lex=council,cat=n,agr={num=sing,per=3}}]
]
Auf der syntaktischen Ebene werden Wörter, Phrasen oder Sätze als Bäume im Sinne ihrer Konstituentenstruktur dargestellt. Jeder Knoten eines solchen Syntaxbaumes wird dabei durch eine Merkmalsstruktur repräsentiert. Baumstrukturen auf der relationalen Ebene unterscheiden sich rein syntaktisch nicht von den Syntaxbäumen. Man unterscheidet zwischen syntaktischen und relationalen Ebenen, unabhängig von rein pragmatischen Gesichtspunkten, wegen der unterschiedlichen Erstellungsmöglichkeit der Strukturen. Syntaxbäume entstehen während des Analyseschrittes aus morphologischen Strukturen mittels eines Parsers. Relationale Strukturen entstehen immer nur durch Transformation aus anderen Baumstrukturen.
Beispiel 2.2: Darstellung einer Baumstruktur
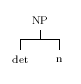
{cat=np,det=def,agr={num=sing,per=3}}.
[
{'word#'=1,string=the,lex=art,cat=det,type=def,agr={per=3,num=sing}},
{'word#'=2,string=council,lex=council,cat=n,agr={num=sing,per=3}}
]
In einer CAT2-Grammatik dienen die Generatoren der Definition von wohlgeformten linguistischen Strukturen. Welche Repräsentationsebene von einem Generator beschrieben wird, muß mit einer Compilerdirektive festgelegt werden.
@level( LEVEL / TYPE / LANGUAGE ).
LEVEL ... Name der Repraesentationsebene
TYPE ... morph, syntactic, relational
LANGUAGE ... Bezeichnung der Sprache
Ein Generator 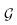 kann formal definiert werden als ein Tupel aus
einer nichtleeren Menge von Konstruktoren
kann formal definiert werden als ein Tupel aus
einer nichtleeren Menge von Konstruktoren 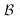 und einer
möglicherweise leeren Menge von Filtern
und einer
möglicherweise leeren Menge von Filtern 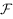 .
.

Beispiel 3: B-Regel
np = {cat=np,det=T,agr=A}.[ ^{cat=det,type=T,agr=A},
^{cat=num,agr=A},
{cat=n,agr=A} ].


Eine F-Regel ist nicht auf alle möglichen Bäume anwendbar, sondern immer nur auf solche, die die geforderte Struktur haben und in allen Teilen den Bedingungen der F-Regel genügen. Jede Knotenbeschreibung einer F-Regel wird in eine Implikation aus Bedingungsteil und Konsequenz überführt. Enthält eine Knotenbeschreibung keine Implikation, wird sie wie eine Bedingung ohne Konsequenz behandelt.
Beispiel 4: F-Regel
f={cat=s,tense=T}.[{cat=np,agr=A},{}>>{agr=A,tense=T},*].
Genügt ein Baum den Bedingungen der F-Regel, muß er auch den Konsequenzen
genügen, sonst wird er von der weiteren Behandlung ausgeschlossen.
F-Regeln ohne Konsequenzen sind Defaultregeln. Sie dienen ausschließlich der Zuweisung von neuen Merkmalen.
Beispiel 5: Defaultregel
per3 = {cat=(n;det),agr={per=3}}.[]
Die Anwendung der F-Regeln auf eine Struktur wird in der Reihenfolge
ausgeführt, wie sie in der Grammatik erscheinen. Diese Ordnungsrelation
ermöglicht es Defaultregeln, Merkmale zu einer Struktur hinzuzufügen, und
erst anschließend die Struktur von anderen Filterregeln verifizieren zu
lassen. Diese Vorgehensweise ist ein prozedurales Element in dem ansonsten
deklarativen Formalismus.
F-Regeln werden in der Praxis sehr extensiv benutzt, während die Menge der verwendeten B-Regeln äußerst minimal ist.
Die Grammatikregeln eines Translators sollen alle Baumstrukturen einer Repräsentationsebene auf Baumstrukturen einer zweiten Ebene abbilden. Welche Repräsentationsebenen ineinander überführt werden sollen, wird am Anfang des Translators mit einer Compilerdirektive festgelegt.
@level( LEVEL1 <=> LEVEL2 ).
Für beide Repräsentationsebenen muß ein syntaktischer oder ein
relationaler Generator existieren. Ein Translator kann grundsätzlich
bidirektional verwendet werden. Jedoch ist es möglich, einzelne
Regeln nur unidirektional anzuwenden.
Ein Translator 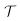 kann formal definiert werden als ein Tupel aus
kann formal definiert werden als ein Tupel aus
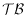 einer nichtleeren Menge von Strukturübersetzungsregeln, T-Regeln,
und
einer nichtleeren Menge von Strukturübersetzungsregeln, T-Regeln,
und  einer möglicherweise leeren Menge von
Merkmalsübersetzungsregeln, TF-Regeln.
einer möglicherweise leeren Menge von
Merkmalsübersetzungsregeln, TF-Regeln.
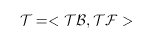

Beispiel 6: T-Regel
np = {cat=np,det=T}.
[^{lex=art,type=T},
^a:{cat=num},
b:{cat=n} ] <=> {cat=n}.[b,^a].
Eine T-Regel ist auf ein Objekt anwendbar, wenn es

Beispiel 7: TF-Regel
np_agr={cat=np}>>{agr=A,det=T}.[+] <=> {cat=n}>>{agr=A,det=T}.[+].
Viele Grammatikregeln können so universell formuliert werden, daß sie in Grammatiken verschiedener Sprachen Verwendung finden. Um diese Regeln nicht in jeder Grammatik neu aufführen zu müssen, werden sie gesondert verwaltet. Diese Verwaltungsebenen werden Common genannt.
@common(NAME).
In andere Ebenen können sie mit der @call-Direktive eingefügt werden.
@call(NAME).
Es ist von Vorteil, für jede universelle Regel
eine eigene Common-Ebene zu definieren. Dann kann sie unabhängig
von anderen Regeln in die betreffenden Grammatiken aufgenommen werden.